How we moved from zero to a viable AI solution with headless CMS
As a SaaS vendor, everyone expects you to have an AI story regardless of what your product is. How do you avoid the current hype and leverage AI to build something truly helpful?
In this article, I’ll tell you the story of approaching AI from a SaaS product vendor perspective and explain how the different roles within the company wanted to integrate it. I’ll explain the basic steps toward a functional prototype, the key lessons learned, and how we turned the experimental code into production-ready features.
How it all started
At the start, we wanted AI to be a significant part of our product to step up our game. And even though we experimented with various cognitive services, such as image and sentiment analysis, we didn’t have a clear vision of leveraging the AI capabilities in our product in general.
The first struggle we had to overcome indeed came from that. Our developers roughly knew what was possible but couldn’t imagine what the user interaction could look like, while product managers and UX designers had some ideas but were accompanied by a feeling that it might be too much on the technical side to ask the developers.
From my point of view, this both-way psychological barrier broke at the point when GPT-3 emerged. It was a moment when many people realized that LLM became usable enough to fulfill a lot of complex tasks without having to define an exact complex algorithm. GPT-2 has shown the direction somewhat earlier, but its results were often questionable, especially in more complex scenarios. Similar to the first versions of DALL-E vs Midjourney, which was a whole new level. See for yourselves:
Difference between DALL-E 2 and Midjourney
Note: This example comes from this article, where you can find some more examples.
That being said, usable and highly capable models (like davinci) actually existed even before GPT-3, but people simply didn’t realize their potential at the time.
Anyway, as people lost their inhibitions with GPT-3 incoming, the gap between design ideas and technical realization closed, and we were able to move forward.
Clarifying the AI integration process
Opening the door to AI capabilities in a rapidly evolving LLM market created a whole new world of possibilities. So many options and just a few vague ideas to start with.
We wanted both to deliver quickly but also deliver something useful with added value.
There were several decision points we had to consider:
Prompt engineering is quite complex on its own, and we couldn’t expect our non-technical users to write good prompts; we needed to do that heavy lifting for them.
The integration had to be simple enough to develop because the primary goal at that point was to test the idea and learn.
The overall idea had to bring additional value over doing the same in a ChatGPT window and copy-pasting the result back to the CMS. It had to be natively integrated rather than in the form of a general extension with limited capabilities.
We didn’t want to get stuck on over-analysis.
At that point, mainly to prevent over-analysis, we decided that our very first goal would be focused on transforming existing content all the way from the user to the AI and back. We figured out that as long as we’d be able to replicate this pipeline with another prompt, it wouldn’t matter what the first implemented scenario would be.
The first scenario
We decided to do a proof of concept based on a couple of scenarios, all sharing a similar interaction pattern:
Users select some content in the rich text editor.
They choose an action the AI will perform on the selected content (a simple pick from predefined options).
The selected content is sent to the AI together with an instruction—a prompt.
The transformed content is shown to the user as a suggestion.
The user can choose to apply the suggestion and replace the originally selected content or copy it to the clipboard.
Overall, a very simple interaction, a single call to the AI, a prompt being crafted by us.
This probably sounds very familiar. It’s an interaction that many tools have chosen as it is the easiest thing you can do as a newbie.
This was just our start game. Our goal was to learn more and decide on the next steps.
The first prototype and challenges
The first prototype took just a few days, and it was running against Azure OpenAI REST API.
However, we quickly found out that the first excitement only applied to very simple cases, such as plain text, which is the native input of the LLM, especially with GPT-3 and earlier, which didn’t work well with formatted content.
We wanted to bring more value than what you would get with copy-pasting the content to the ChatGPT window and back. Because any user can do that themselves. Moreover, you lose all the existing formatting and other metadata in the process, potentially requiring more from the user than what you provide to them.
So, the following AI skills in our prototype were just scratching the surface from today’s point of view:
Create a title/Summarize – A relatively easy first step that was basically plain-text/plain-text transformation without the complexity around handling formatting.
Fix spelling and grammar – Despite having extensions for these checks widely available, it presented a great use case with minimum text transformations and an expectation to preserve formatting.
Make it shorter/longer – A combination of either new or reduced content together with reasonably preserving formatting.
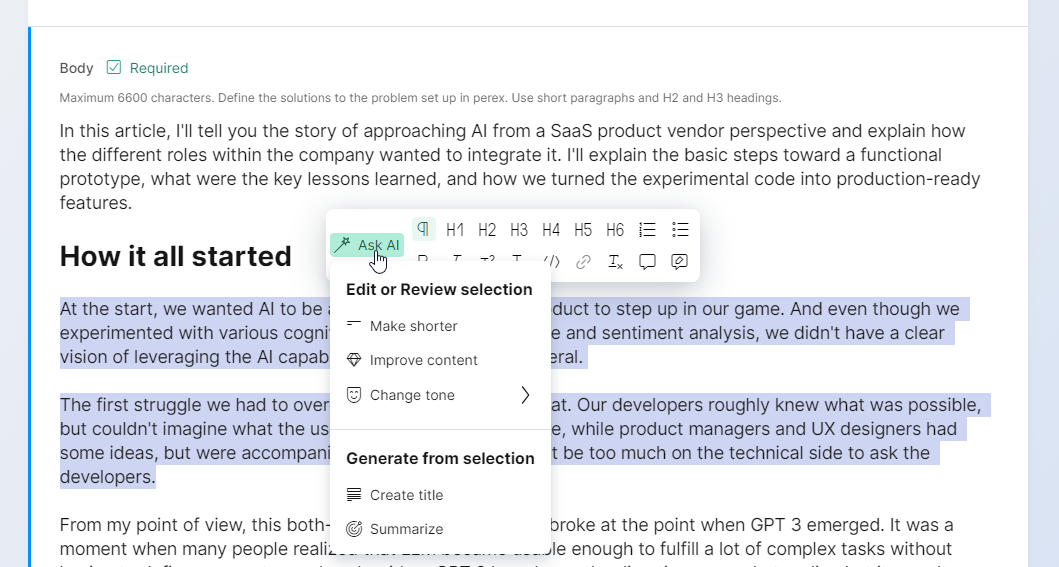
One of the first AI prototypes in Kontent.ai
The goal of implementing these actions was to make sure that we could provide more than just a ChatGPT window and lay down a foundation for advanced AI capabilities.
Note: It is fair to mention that building an integrated AI comes with many more challenges than just handling formatting. It’s not possible to list every one of them here in the scope of this article, so I will leave this topic for a dedicated content piece in the future.
Scaling up the AI implementation team
Until this point, AI prototyping was a one-man show on each involved side, whether it was UX, product management, or development. To increase the impact and speed up delivery, we needed more than just a few individuals.
We dedicated one whole development team together with related support roles to the activity, which enabled us to achieve the following goals in parallel:
Bringing AI to the customers Turn the first prototype into an end-to-end feature available to chosen customers and start gathering feedback from real usage.
Research & vision Research the problem and ensure we have as much data as possible for future development.
Exploring AI capabilities Explore the AI integration possibilities beyond text.
Establishing a proper AI team Lay down a foundation of a team of AI professionals that would drive the advanced AI integrations.
Bringing AI to the customers
While the prototype had been fully functional, as with every new and experimental feature, it needed slight refactoring before it could have been enabled for our customers.
Around that time, we discovered the Semantic Kernel library. This open-source SDK combining AI services with conventional programming languages does a lot of the integration’s heavy lifting and quickly became an industry standard.
We evaluated it against our prototype and later decided to use Semantic Kernel for production features as it freed us from handling low-level integration specifics and allowed us to focus on implementing and extending the AI scenarios.
With this foundation, we were able to offer AI features to a broader range of our customers as an early access feature.
Early access AI features
Research & vision
We have tracked the activities of our early access customers and collected feedback from them to polish and further shape the AI experience in our product.
We experimented a lot with various prompt techniques (especially with GPT-4), learned from AI experts, and tried pushing the limits of what can be done to make the user experience even more integrated.
We tried various strategies on how to work with long content, such as splitting it into more chunks and running each of them with standalone AI requests, etc.
Exploring AI capabilities
The research on using AI beyond text completion and transformation led to several internal prototypes, and we decided to further extend the following four: image generation, categorization, content vectorization (matching and finding relevant content), and natural language processing (Copilot and open prompts).
We have also recently deployed automatic image tagging via our Early access and are actively working on further experiments related to how our users interact with the AI in a more integrated way.
AI or not AI, that’s the question
At this stage, we’ve had a solid foundation of AI integration and a handful of customers happily using it. But this question was still in the air: How much should we push the AI to everyone? The thing is, AI can be very powerful, but with great power comes great responsibility.
We didn’t want to just spit huge amounts of low-quality content. The world has had enough of it already. Our goal was to reduce time spent making quality content and improve the overall ROI.
If a customer doesn’t want to use the AI features for any reason, they don’t have to. We designed the AI integration as an extra option to accelerate things that can be otherwise done manually.
That being said, AI is here to stay, and we encourage everyone to make the most of it by leveraging this AI assistant instead of having to act as a human assistant for others.
The final journey to production
After doing the wider research and making early access available to chosen customers, we added two additional development teams to our AI track with the goal of turning the functional and customer-tested prototype into a real production state.
As I mentioned earlier, we decided to stick with the Semantic Kernel library, which enabled us to accelerate the development. At the time of writing this article, we have already released the Beta version to all of our customers. The journey to production also required us to prepare a whole new backend infrastructure to cope with the amount of AI requests in a scalable way.
And while the front end looks the same, the code behind it is much more robust, reusable, and composable, so we can keep on building more skills on top of it.
Conclusion
In this article, I told you what our journey of approaching AI looked like, all the way from the first steps to gaining enough experience in this area to have a solid foundation for our future AI projects.
What if we told you there was a way to make your website a place that will always be relevant, no matter the season or the year? Two words—evergreen content. What does evergreen mean in marketing, and how do you make evergreen content? Let’s dive into it.
How can you create a cohesive experience for customers no matter what channel they’re on or what device they’re using? The answer is going omnichannel.
To structure a blog post, start with a strong headline, write a clear introduction, and break content into short paragraphs. Use descriptive subheadings, add visuals, and format for easy scanning. Don’t forget about linking and filling out the metadata. Want to go into more detail? Dive into this blog.
Lucie Simonova
Subscribe to the Kontent.ai newsletter
Get the hottest updates while they’re fresh! For more industry insights, follow our LinkedIn profile.