Building your custom documentation portal (when you already have two)
In this article, we'll talk about the process of building our own documentation portal for Kontent.ai and the choices we made.

Written by Jan Cerman

In this article, we'll talk about the process of building our own documentation portal for Kontent.ai and the choices we made.
Written by Jan Cerman
We’re a company that offers CMS software to businesses and individuals. Based on this alone, it would be safe to assume that, when given the choice, we would have picked a CMS for our documentation. Yet the choice to pick a Content-as-a-Service solution as a home for our materials wasn’t immediate. In fact, far from it. A little later, after the idea of building our own portal was born, we trialed several, mostly markdown-based tools for building sites. We had to decide which technology to use and where and how to store our materials.
We considered some of the existing static site generators and adjusting them to our needs. Because what more is a documentation portal than a static site with little to no dynamic content, right? There are many popular tools for generating static sites, such as Jekyll, Hugo, Sphinx, DocFx, or GatsbyJs, to name just a few. We tried these and then a few more and sought to find the right fit. However, we quickly realized that we would need to customize many things regardless of which tool we used. Each tool came with its specific technology stack (be it Node, React, Ruby, or Python) and a way of storing content (be it reStructuredText or any of the latest markdown flavors).
It appeared that having our materials in markdown would be sufficient. But the more we thought about cross-linking, reusability, referencing code samples in articles, or anything slightly non-standard, it occurred to us that we might as well go with a regular CMS. We decided to go for Kontent.ai that would later become a content hub for our educational materials. We chose it because it would take care of the cross-linking, allow for easy reusability of content, and let us create anything we can think of through structured content. Moreover, any new person would only have to learn to use one system instead of two or more.
Our vision behind the whole project was to have a single self-service portal. A portal where users could easily find what they need and feel successful as a result. Simple as that. But we’ve had a long way to go. When we were in the planning phase, we had a long list of external and internal requirements. For customers, the greatest requirement was to let them find everything in one place. For us, over half of the requirements related to the authoring experience because we were having issues in this area with our current 3rd party solutions. To name just a few requirements, we wanted to:
We also wanted to let people contribute to our documentation either through feedback mechanisms in the portal itself or directly in the CMS. Finally, we needed to know what’s going on in the portal and what people do in it. In other words, integrate with analytics services like Google Tag Manager, Amplitude, or Hotjar.
Once we settled on the requirements, it was time to figure out how to model our content within the new CMS. Quite often, you won’t find any WYSIWYG editors in CaaS software. This nudges you to adapt to a new way of thinking about your materials—one where presentation (the way it looks) is separated from content (the way it’s written). Before any implementation began, we looked at our materials and built several prototypes in the CMS to see how the actual work with the new system would look like. For instance, we created models required to write a short article with an image, formatted text, and a callout. This exercise worked quite well. Then we continued with more complex articles that included simple code samples.
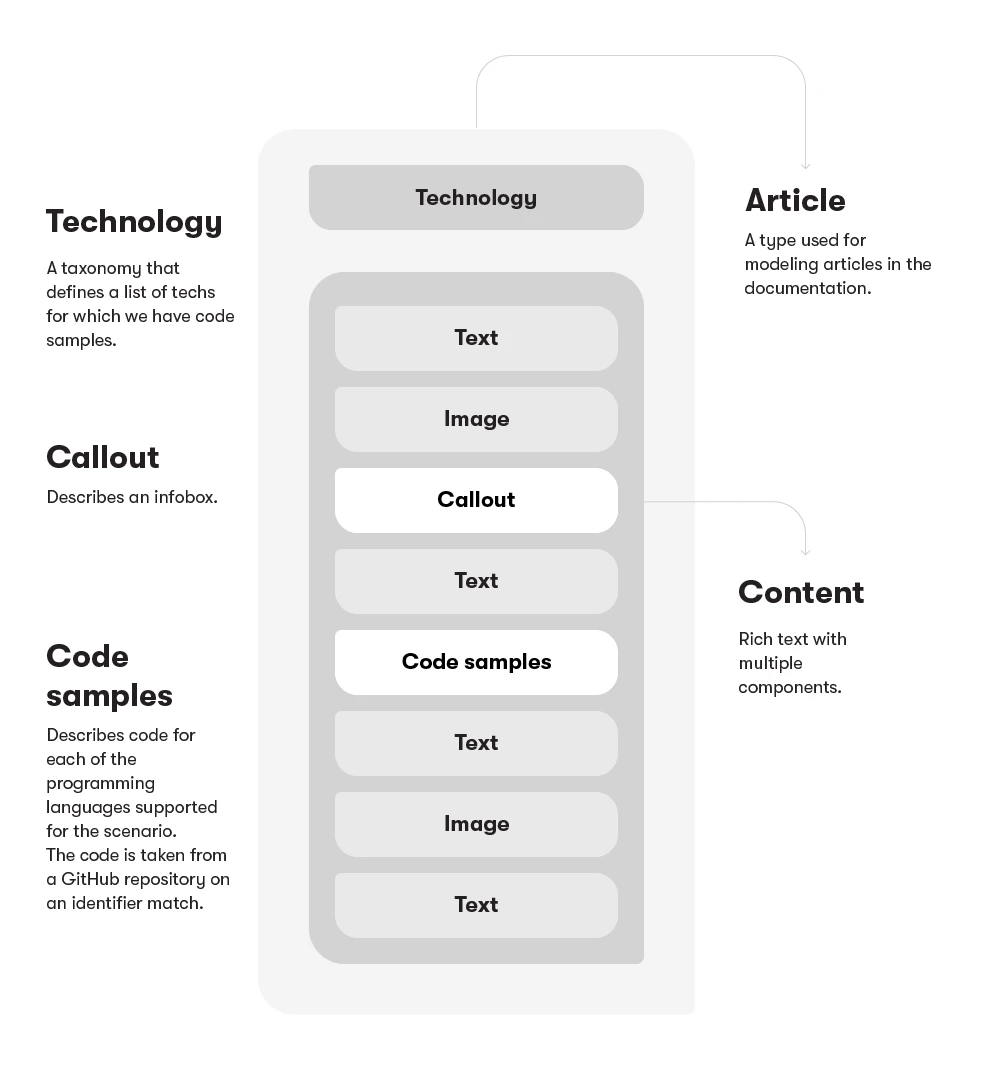
Things got more difficult when we tackled articles with code samples in more programming languages. All of the code samples had to be easily reusable in other articles. But we didn’t stop there. We also wanted articles that could have different (or partially different) content based on the technology readers choose. At the time, we had about ten technologies (for example, plain JavaScript, React, .Net, and so on) to choose from. However, most of the technical articles were written with a smaller number of technologies in mind. This led to a couple of prototyping sessions followed by validation within our team. We quickly dismissed overly complex models and strived for as much simplicity as possible. Making things simpler became an ongoing theme throughout the whole project—we preferred simplicity whenever possible, even if it sometimes meant going back to the drawing board.
The time investment spent on figuring out the right models and approaches before any migration or implementation had begun gave us a deeper understanding of the new solution. Having the models described visually helped when presenting the ideas to our developers. We showed them our existing articles, put them side by side with the model prototypes, and deconstructed the individual parts into separate components together. Soon enough, structured content started to make sense to everyone.
When we had a rough idea of what the models would look like, it was time to split the whole project into deliverable parts. One of the advantages of CaaS is that you can release iteratively, shipping each part to customers as soon as it’s available. This approach meant we could have improved the portal before it was finished altogether. We would also adopt the new solution gradually and migrate our existing content piece by piece instead of all at once. Win-win. It also allowed our regular work to continue without any downtime, save for time spent migrating our API references into something completely different. But more on that later.
Now, let’s take a look at the diagram below. We had our materials in two places for the two main personas. These were two 3rd party Software-as-a-Service (SaaS) solutions. While they worked well on their own and for the purposes we originally chose them, they fragmented the whole experience for our customers. It was time to move to everything under one hood. We had to ensure everything kept working throughout this endeavor
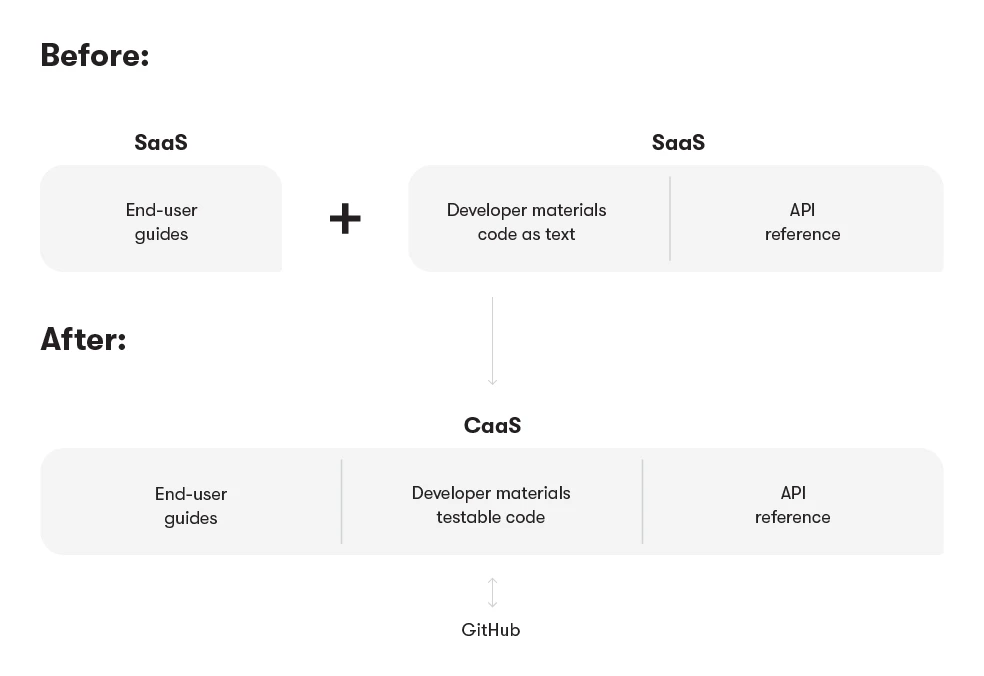
We split the project into three major phases. Each phase covered a different segment of our materials (end-user guides, developer materials, and API reference) and increased in complexity both from the technical standpoint and content-wise. Here’s what our release plan looked like:
1. Releasing the core of the portal with end-user guides.
2. Adding code samples and technical articles to the portal.
3. Adding API reference content to the portal.
The core of the portal was a minimum viable product for us. It had to do search right, it had to display end-user guides correctly, and it had to be reliable.
Our API documentation used to be a single long page with all APIs stuck together. Our goal was to redesign the documentation so that the APIs were separate. We also wanted to highlight the code samples within the reference materials and simplify the way content was put together and displayed. In general, API reference content is highly structured—each API may have a couple of operations, each operation returns at least one object, each object consists of a list of properties, and each property has its own set of metadata. The API documentation we had before the redesign contained a lot of manually-written tables created to describe these structures. And if you didn’t know, let me tell you that tables, especially bigger ones in markdown, are a pain to work with and maintain. When deciding how to approach this part of the project, we asked ourselves, “Is it worth doing it from scratch?” The question lingered in the air for a bit, and we shortly contemplated designing and creating our own visuals for the API documentation, but the answer was, “Not really, no.“
We started looking for tools that could generate API documentation for us, and one that caught our attention was ReDoc. ReDoc can generate API reference documentation based on the OpenAPI specification you feed it, which is great. The only issue? We didn’t have any OpenAPI specification, yet. Our reference content consisted of four REST APIs, a JavaScript API, and a few articles. All written manually and stored within a 3rd party SaaS solution. The OpenAPI specification seemed to support everything we needed for documentation purposes. The tooling and community around the specification were very active. In addition, the specification supported reusing content, which is what we were already doing within Kontent.ai itself. So far so good.
Now the problem with the decision to go all in on OpenAPI was that it would essentially mean we would fragment our authoring experience—articles would be authored in the CMS, and REST APIs would be authored using OpenAPI and most likely stored on GitHub. Suddenly, new questions emerged. How do you link between the two? How do you share content between the two? How do you schedule releases so that the two remain in sync?
The requirements I outlined earlier still applied here. To fulfill them, we needed to adjust the plan and go back to prototyping models for the CMS. Only this time, it wasn’t about articles and code samples, it was about mirroring the OpenAPI specification within Kontent.ai. It meant more than a dozen new models and a document outlining the relation between the CMS models and the specification. Luckily, we didn’t need to cover every aspect of the OpenAPI specification, just the parts required to describe our REST APIs. Still, that was about 80% of what the specification offers. Then the developers would create a few services to take care of translating the content from the CMS into OpenAPI specifications for each API, and we’re golden.
After our authoring team had tackled the learning curve, we started using and enjoying the things we didn’t have before. Publishing new versions of articles is now a breeze as we don’t have to duplicate content anymore to prepare the new versions. We started to schedule our content to be published at a specific time—especially helpful in an environment with regular releases. The review process also improved significantly because of the comments in Kontent.ai. These let the reviewers comment on specific parts of the content and offer guidance within the authoring environment. This means less context switching and more focus. Also, publishing smaller changes is now twice as fast because we spend less time looking for specific content.
With all the materials together, we can easily cross-link and reuse content across any type of content. This means we can create a small piece of content, such as a callout, and use it within articles and API references alike. The CMS and the portal take care of it. With the API reference content converted to OpenAPI, we can automate generating Postman collections and save time. Moreover, having the APIs described using a standardized specification opens doors to more integration scenarios for us and our customers.
Lastly, analytics. Once you know what people are looking for on your site and where they (don’t) spend their time, you can use that information to continuously improve your materials and allocate your time better. For instance, we now have a good idea of what people search for and whether they find it. If they do, that’s good. If they don’t, that’s a signal for action.
Looking back at the whole project, it was a fun challenge and learning experience for everyone. If we had to do it again, I’m sure we would do a few things differently. That’s part of the journey. Overall, the outcome has been great so far. If you’re intrigued and want to know more, stay with us for the next installment of this series where we’ll go into our approach to content modeling, content versioning, localization, and managing code samples within Kontent.ai.

What if we told you there was a way to make your website a place that will always be relevant, no matter the season or the year? Two words—evergreen content. What does evergreen mean in marketing, and how do you make evergreen content? Let’s dive into it.
Lucie Simonova

How can you create a cohesive experience for customers no matter what channel they’re on or what device they’re using? The answer is going omnichannel.
Zaneta Styblova

To structure a blog post, start with a strong headline, write a clear introduction, and break content into short paragraphs. Use descriptive subheadings, add visuals, and format for easy scanning. Don’t forget about linking and filling out the metadata. Want to go into more detail? Dive into this blog.
Lucie Simonova